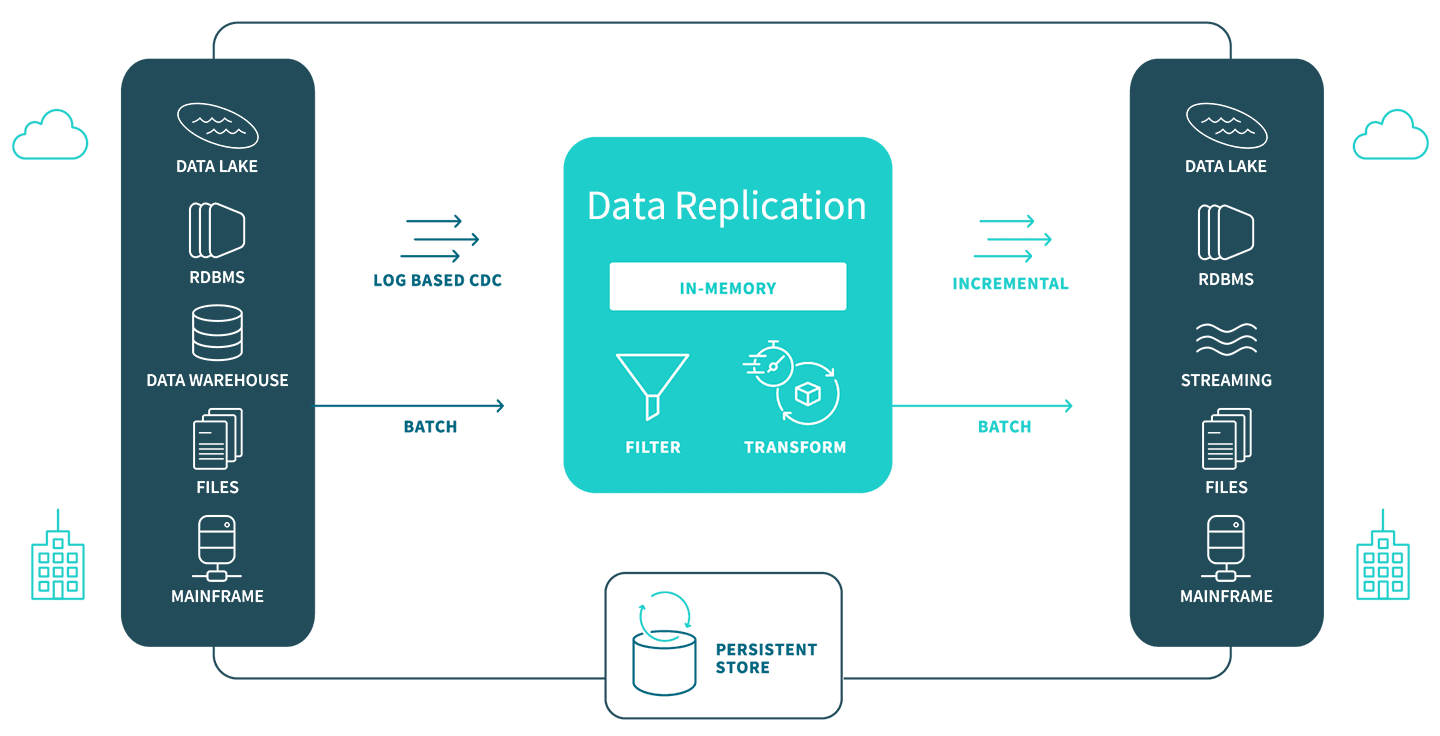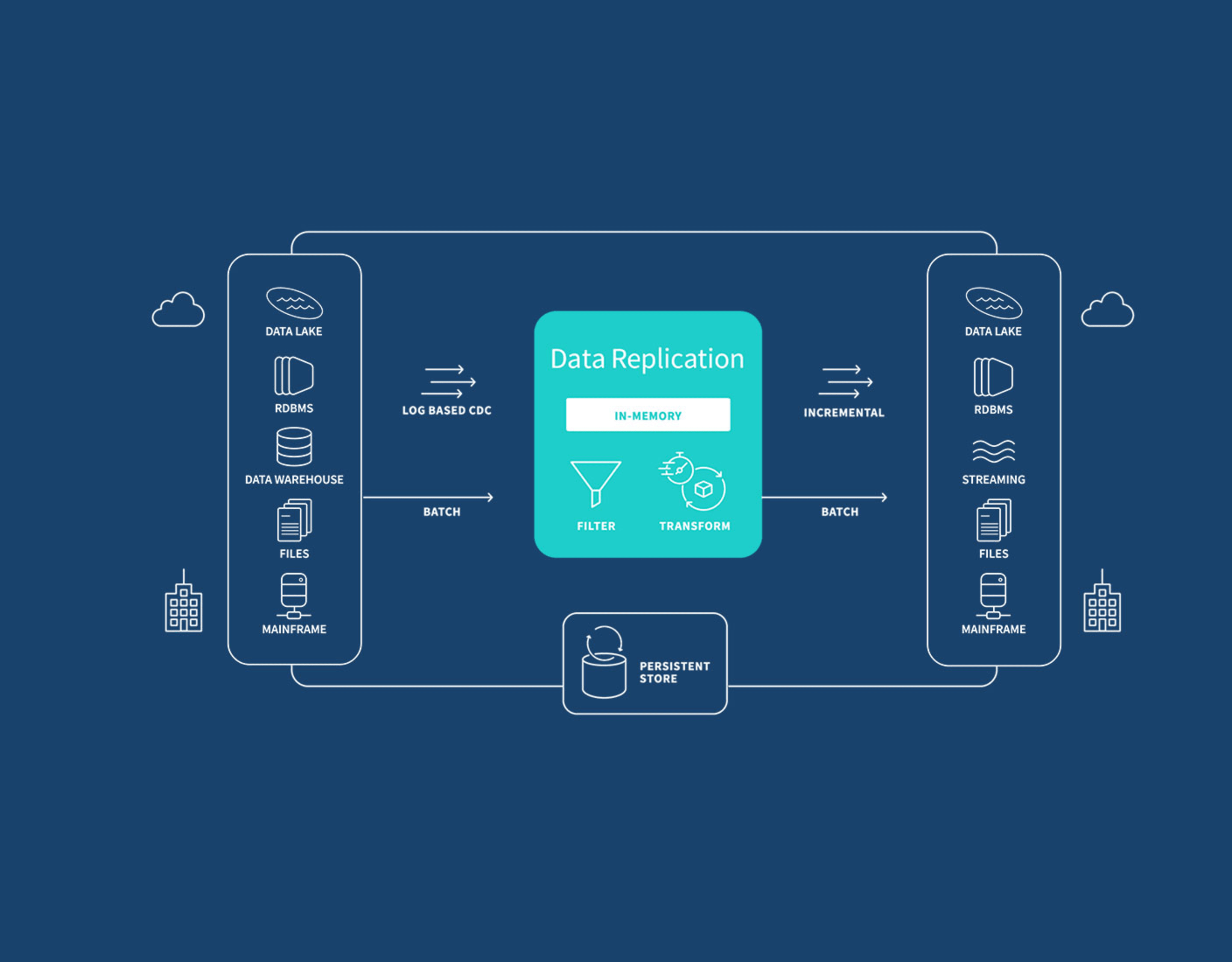
Benefits of Replicating Data
Data replication efficiently and securely moves data across heterogeneous databases, data warehouses, and big data platforms within your organization, overcoming geographical dispersion, data access demands, and complex storage challenges. This enhances database and application performance, facilitates technology integration, and enables data analytics on non-production systems, improving your overall IT infrastructure.
The brief video below describes the key concepts, benefits and challenges of data replication.
Below are the key benefits of replicating data in your organization.
Business stakeholder benefits:
Single source of truth. Data replication helps you bring together data from different sources and repositories and lets you explore and analyze governed data. This gives you a trusted, holistic picture for analytics and helps you uncover insights that improve your business.
Real-time data. You can access up-to-date information from the nearest or fastest replica, leading to faster response times.
Faster insights. Get faster access to the data you need because you can use replicated data for analytical purposes such as data mining, reporting, and BI tasks without affecting production systems.
Offline access and mobile apps: Database replication supports offline access to data and enables the functionality of mobile applications in scenarios with limited or intermittent connectivity.
IT/DataOps benefits:
Enhanced Data Availability and Redundancy: Replication guarantees multiple data copies on different systems, mitigating data loss risks and bolstering system resilience against failures.
Load Balancing and Performance Optimization: Distributing data across systems improves performance through load balancing, alleviating bottlenecks and optimizing resource utilization.
Disaster Recovery and Business Continuity: Quick data recovery post-disaster minimizes downtime, ensuring uninterrupted business operations and data integrity.
Global Data Distribution and High Application Availability: Database replication to multiple locations enables low-latency global access, while redundant data copies provide high availability and fault tolerance for critical applications.